concordance-nf¶
The concordance-nf pipeline is used to detect sample swaps and determine which wild isolate strains should be grouped together as an isotype.
To determine which strains belong to the same isotype we use two criteria. First we look at the strains that group together with a concordance threshold of 99.95%. Generally this will group most isotypes without issue. However, it is possible that you will run into cases where the grouping is not clean. For example, strain A groups with B, B groups with C, but C does not group with A. In these cases you must examine the data closely to identify why strains are incompletely grouping. Our second criteria we use to group isotypes may address these types of groupings.
The second criteria that we use to group isotypes regards looking for regional differences among strains. If two strains are similar but possess a region of their genome (binned at 1 Mb) that differs by more than 2% then we will separate them out into their own isotypes.
The process of grouping isotypes is very hand-on. This pipeline will help process the data but you must carefully review the output and investigate closely.
Pipeline overview¶
┌─┐┌─┐┌┐┌┌─┐┌─┐┬─┐┌┬┐┌─┐┌┐┌┌─┐┌─┐ ┌┐┌┌─┐
│ │ │││││ │ │├┬┘ ││├─┤││││ ├┤───│││├┤
└─┘└─┘┘└┘└─┘└─┘┴└──┴┘┴ ┴┘└┘└─┘└─┘ ┘└┘└
parameters description Set/Default
========== =========== =======
--debug Set to 'true' to test false
--cores Regular job cores 4
--out Directory to output results concordance-{date}
--vcf Hard filtered vcf null
--bam_coverage Table with "strain" and "coverage" as header null
--info_sheet Strain sheet containing exisiting isotype assignment null
--species 'c_elegans' will check for npr1. All other values will skip this null
--concordance_cutoff Cutoff of concordance value to count two strains as same isotype 0.9995

Software Requirements¶
- The latest update requires Nextflow version 20.0+. On QUEST, you can access this version by loading the
nf20conda environment prior to running the pipeline command:
module load python/anaconda3.6
source activate /projects/b1059/software/conda_envs/nf20_env
Alternatively you can update Nextflow by running:
nextflow self-update
Usage¶
Profiles¶
The nextflow.config file included with this pipeline contains three profiles. These set up the environment for testing local development, testing on Quest, and running the pipeline on Quest.
local- Used for local development. Uses the docker container.quest_debug- Runs a small subset of available test data. Should complete within a couple of hours. For testing/diagnosing issues on Quest.quest- Runs the entire dataset.
Note
If you forget to add a -profile, the quest profile will be chosen as default
Debugging the pipeline on Quest¶
When running on Quest, you should first run the quest debug profile. The Quest debug profile will use the test dataset and sample sheet which runs much faster and will encounter errors much sooner should they need to be fixed. If the debug dataset runs to completion it is likely that the full dataset will as well.
nextflow run andersenlab/concordance-nf -profile quest_debug -resume
Running the pipeline on Quest¶
Note: if you are having issues running Nextflow or need reminders, check out the Nextflow page.
The pipeline can be run on Quest using the following command:
nextflow run andersenlab/concordance-nf -profile quest --bam_coverage <path_to_file> --vcf <path_to_file> --species c_elegans --info_sheet <path_to_file> -resume
Parameters¶
The nextflow profiles configured in nextflow.config are designed to make it so that you don't need to change the parameters. However, the pipeline offers this flexibility if it is ever called for.
--bam_coverage¶
The sample sheet to use. This is generally the same sample sheet used for wi-gatk. The sample sheet should look like this:

Important
It is essential that you always use the pipelines and scripts to generate this sample sheet and NEVER manually. There are lots of strains and we want to make sure the entire process can be reproduced.
--vcf¶
The hard-filtered VCF output from wi-gatk.
--info_sheet¶
Strain sheet containing existing isotype assignment. You can download the current wild isolate species master sheet for this input.
--species (optional)¶
Common options include 'c_elegans', 'c_briggsae', and 'c_tropicalis'. If species == c_elegans, pipeline will check for npr-1 variant, otherwise this step will be skipped. Default = 'c_elegans'
--concordance_cutoff (optional)¶
Cutoff to use to determine isotype groups. Default is 0.9995.
--cores (optional)¶
The number of cores to use during alignments and variant calling.
--out (optional)¶
A directory in which to output results. By default it will be concordance-YYYYMMDD where YYYYMMDD is todays date.
Output¶
├── concordance
├── gtcheck.tsv
├── isotype_count.txt
├── isotype_groups.tsv
├── npr1_allele_strain.tsv
├── problem_strains.tsv
├── WI_metadata.tsv
├── concordance.pdf/png
├── xconcordance.pdf/png
└── pairwise
└── within_group
└── {isotype_group}.{isotype}.{strain1}_{strain2}.png
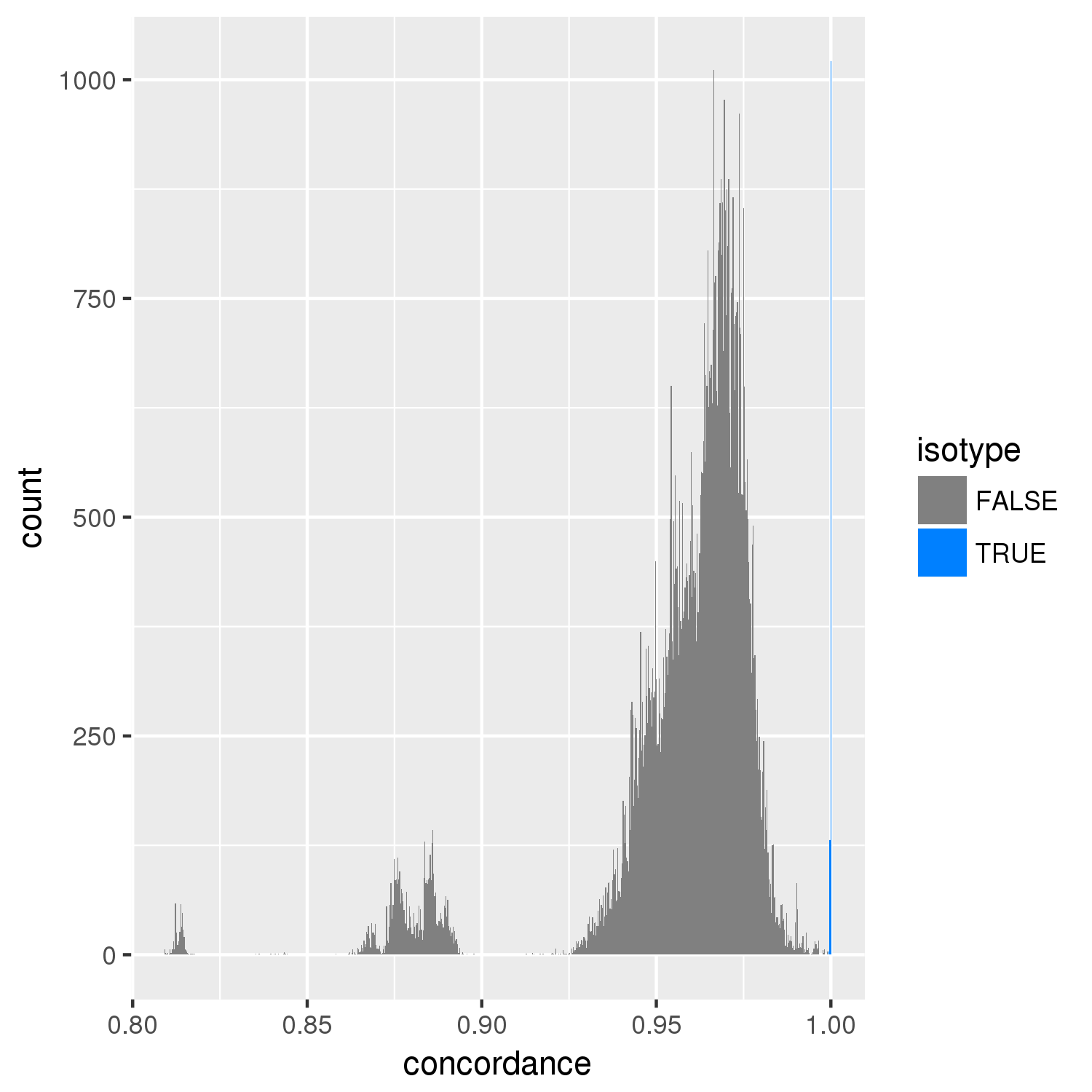
- concordance.png/pdf - An image showing the distribution of pairwise concordances across all strains. The cutoff is at 99.9% above which pairs are considered to be in the same isotype unless issues arise.
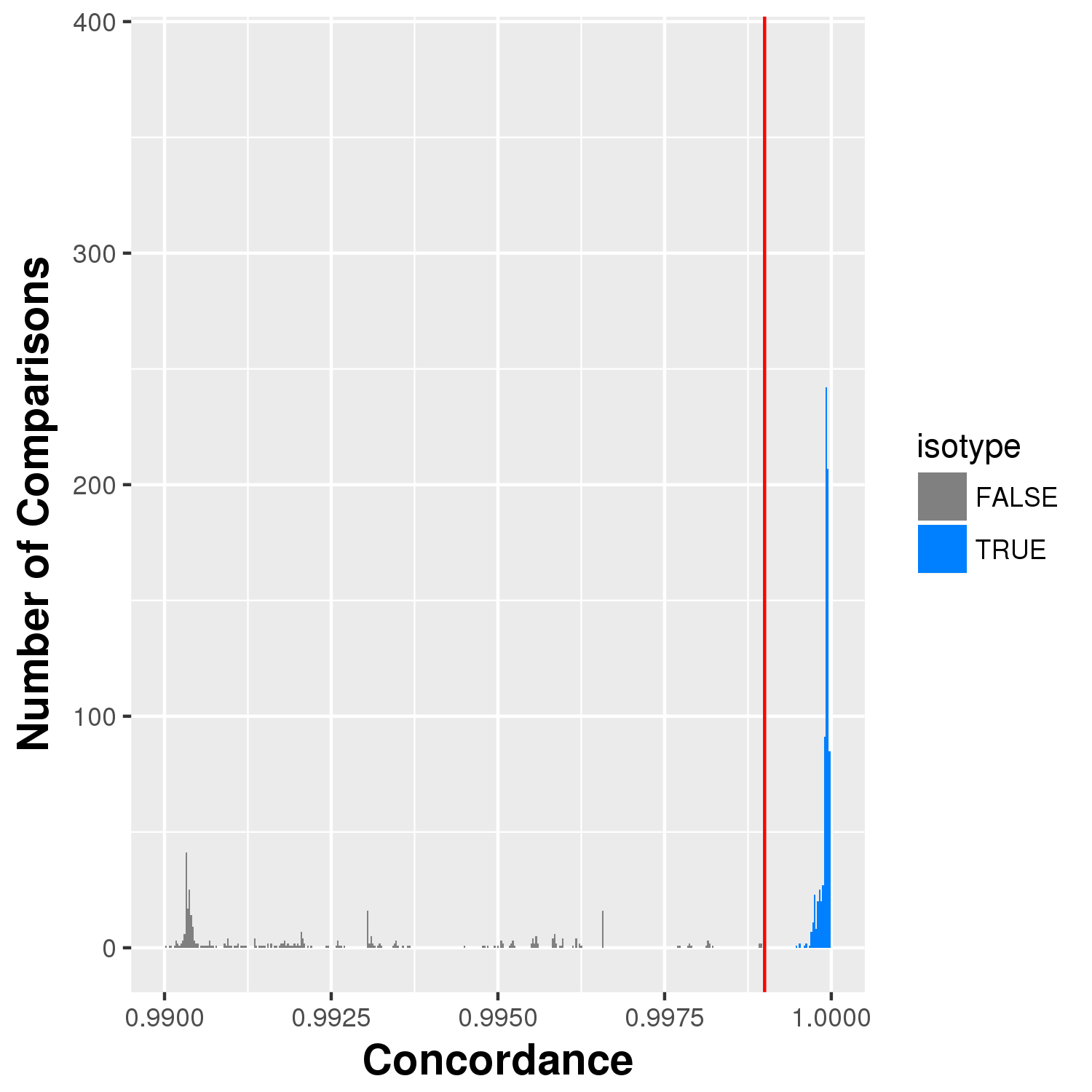
- xconcordance.png/pdf - A close up view of the concordances showing more detail.
- isotype_groups.tsv - This is the one of the most important output files. It illustrates the isotypes identified for each strain and identifies potential issues.
A file with the following structure:

- group - A number used to group strains (in each row) into an isotype automatically. This number should be unique with the isotype column (e.g. 1--> AB1, 112 --> CB4858, BRC20067 --> 175). The number can change between analyses.
- strain - the strain
- isotype - the currently assigned isotype for a strain taken from the
WI Strain Infospreadsheet. When new strains are added this is blank. - latitude
- longitude
- coverage - Depth of coverage for strain.
- unique_isotypes_per_group - Number of unique isotypes when grouping by the group column. This should be 1. If it is more than 1, it indicates that multiple isotypes were assigned to a grouping and that a previously assigned isotype is now being called into question.
- unique_groups_per_isotype Number of unique groups assigned to an isotype. This should be 1. If it is higher than 1, it indicates that a strain is concordant with strains in two different isotypes (including blanks). If it is equal to 2 and contains blanks in the isotype column it likely means that an isotype should be assigned to that strain.
- strain_in_multiple_isotypes - Indicates that a strain is falling into multiple isotypes (a problem!).
- location_issue - Indicates a location issue. This occurs when strains fall into an isotype but are located far away from one another. Some are known issues and can be ignored.
- strain_conflict -
TRUEif any issue is present that should be investigated.
Note
This file might change as you manually adjust the concordance cutoff for each run
-
gtcheck.tsv - the other most important file. File produced using
bcftools gtcheck; Raw genotype differences between strains. This file is used in manual inspection of the isotype groups -
isotype_count.txt - Gives a count of the number of isotypes identified.
-
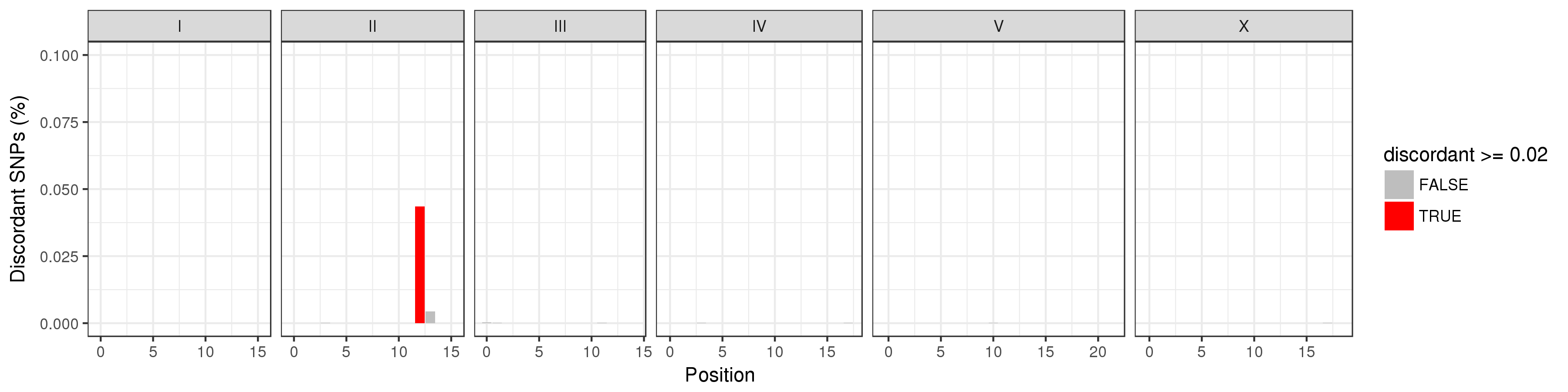
concordance/pairwise/ (directory)
Contains images showing locations where regional discordance occurs among strains classified as being the isotype. You must look through all these images to ensure there are no strains being grouped that have regions with significant differences (> 2%). The image below illustrates an example of this. ED3049 and ED3046 are highly similar (> 99.9%). However, they differ in a region on the right arm of chromosome II. We believe this was enough reason to consider them separate isotypes.
- npr1_allele_strain.tsv - if species == c_elegans, this file will be output to show problematic strains that contain the N2 npr-1 allele and should be manually checked.
Important
If a new strain is flagged in this file, tell Erik, Robyn, and the wild isolate team ASAP so they can address the issue. This strain will likely be removed from further analysis.